Ставь лайки и следи за новостями
Поставь на него ссылку - пусть другие тоже оценят
Оцени его работу в терминале MetaTrader 5
- Просмотров:
- 19174
- Рейтинг:
- Опубликован:
- 2016.06.14 18:36
- Обновлен:
- 2016.11.22 07:32
-
 Вы упускаете торговые возможности:
Вы упускаете торговые возможности:- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация ВходВы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
-
 Нужен робот или индикатор на основе этого кода? Закажите его на бирже фрилансеров
Перейти на биржу
Нужен робот или индикатор на основе этого кода? Закажите его на бирже фрилансеров
Перейти на биржу
Автор:
gpwr
История версий:
06/26/2009 - добавлен новый индикатор BPNN Predictor со Smoothing.mq4, в котором цены сглаживались перед прогнозированием с использованием EMA.
08/20/2009 - в коде исправлен расчет функции активации нейронов, чтобы предотвратить арифметическое исключение; обновлены BPNN.cpp и BPNN.dll
08/21/2009 - добавлено очищение памяти после исполнения DLL; обновлены BPNN.cpp и BPNN.dll
Вкратце о теории нейронных сетей:
нейронные сети — регулируемая модель, в которой выход — это функция входа. Она состоит из нескольких уровней:
- входной уровень, который содержит входные данные;
- скрытый уровень, содержащий узлы обработки, которые и называются нейронами
- выходной уровень, состоящий из одного или нескольких нейронов, выходные данные которых являются выходными данными всей сети.
Все узлы смежных уровней соединены между собой. Эти соединения называются синапсами. Каждый синапс имеет назначенный коэффициент, по которому данные, передающиеся через синапс, умножаются. Этот коэффициент называется весовым (w[i][j][k]). В нейронной сети прямого распространения (Feed-Forward Neural Network, FFNN) данные распространяются от входов к выходам. Здесь пример FFNN с одним входным слоем, одним выходным и двумя скрытыми слоями.
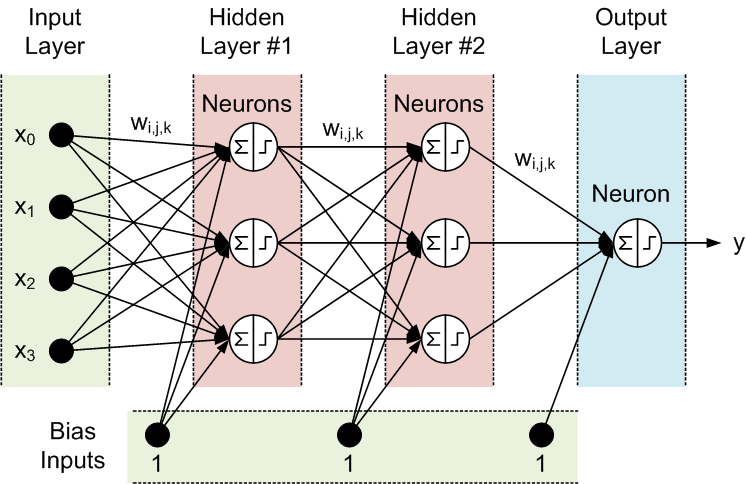
Топология FFNN часто сокращается следующим образом: <# входов> - <# нейронов в первом скрытом слое> - <# нейронов во втором скрытом слое> -...- <# выходов>. Сеть, изображенная выше, может быть обозначена как 4-3-3-1.
Данные обрабатываются нейронами в два этапа, соответственно обозначенные на рисунке знаками суммирования и ступеньки.
- Все входные параметры умножаются на связанные с ними весами и суммируются.
- Итоговые суммы обрабатываются функцией активации нейронов, чей выходной параметр и есть выходной параметр нейрона.
Это функция активации нейронов, которая дает нелинейность в модели нейронной сети. Без этого нет смысла в скрытых слоях, а сама нейронная сеть становится просто линейной авторегрессионной моделью.
Вложенные файлы библиотек функций нейронных сетей позволяют выбрать одну из трех функций активации:
- сигмоид sigm(x)=1/(1+exp(-x)) (#0)
- гиперболический тангенс tanh(x)=(1-exp(-2x))/(1+exp(-2x)) (#1)
- рациональная функция x/(1+|x|) (#2)
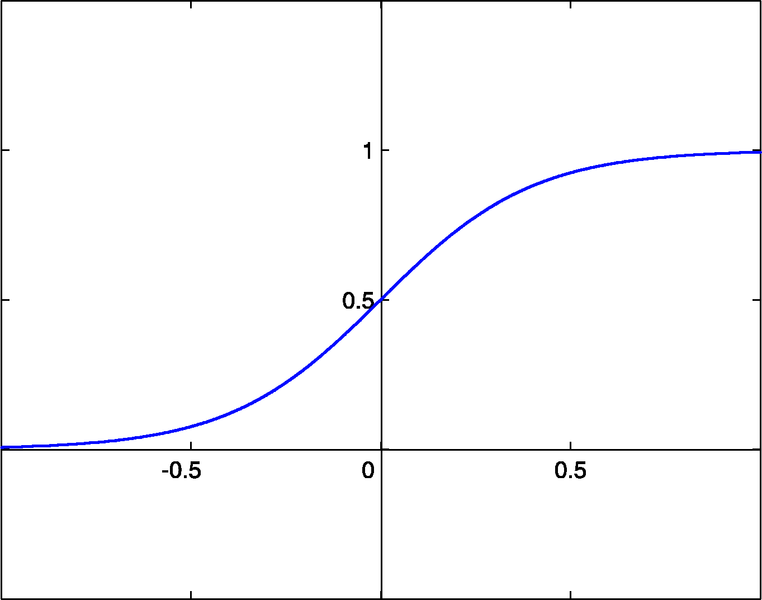
Порог активации этих функций x=0. Этот порог может быть сдвинут вдоль оси X благодаря дополнительным входным параметрам каждого нейрона, так называемому входному смещению, которое также имеет собственный вес.
Количество входов, выходов, скрытых слоев, нейронов в них и значения весов синапсов полностью описывает FFNN, то есть, нелинейную модель, которую она создает. Чтобы найти значения весов, сеть необходимо обучить. Во время обучения с учителем в сеть поступают несколько наборов прошлых входных параметров и соответствующие им ожидаемые выходы. Веса оптимизированы для достижения наименьшей погрешности между ожидаемыми выходами и теми, что дала сеть. Простейший метод оптимизации весов - обратное распространение ошибок, которое представляет собой метод градиентного спуска. Прилагаемая сюда обучающая функция Train() использует вариант этого метода, называемый Improved Resilient back-Propagation Plus (iRProp+). Метод описан здесь:
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.17.1332
Основной недостаток градиентных методов оптимизации на основе градиентов — в том, что они часто находят локальный минимум. ДЛя таких неупорядоченных рядов, как, например, ценовые, поверхность ошибок обучения имеет очень сложную форму с большим количеством локальных минимумов. Для таких данных лучше подходит такой метод обучения, как генетический алгоритм.
Прилагаемые файлы:
- BPNN.dll - файл библиотеки
- BPNN.zip - архив всех файлов, необходимых, чтобы скомпилировать BPNN.dll в C++
- BPNN Predictor.mq4 - индикатор, прогнозирующий будущие цены открытия
- BPNN Predictor with Smoothing.mq4 - индикатор, прогнозирующий сглаженные цены открытия
Файл BPNN.cpp содержит две функции: Train() и Test(). Train() используется для обучения сети на основе полученных входных данных и ожидаемых выходных значений. Test() используется для вычисления выходов сети с использованием оптимизированных весов, найденных посредством функции Train().
Здесь список входных (зеленые) и выходных (синие) параметров Train():
double inpTrain[] - входные обучающие данные (одномерный массив, содержащий двухмерные данные, первыми идут те, что получены ранее)
double outTarget[] - выходные ожидаемые данные для обучения (двухмерные данные в одномерном массиве, первыми идут старейшие)
double outTrain[] - одномерный массив выходных данных, хранящий выходные данные сети, полученные в процессе обучения
int ntr - # наборов обучения
int UEW - Use Ext. Веса для инициализации (1=use extInitWt, 0=use rnd)
double extInitWt[] - одномерный массив входных параметров для хранения трехмерного массива внешних начальных весов
double trainedWt[] - Одномерный массив выходов для хранения трехмерного массива весов, полученных в процессе обучения
int numLayers - # слоев, включая входной, скрытые и выходной
int lSz[] - # нейронов в слоях. lSz[0] # входов сети
int AFT - тип функции активации нейронов
int OAF - 1 — разрешенная функция активации для выходного слоя i; 0 — запрещенная
int nep - Максимальное # эпох обучения
double maxMSE - Максимальное MSE; обучение останавливается в тот момент, когда однократно достигается maxMSE.
Здесь список входных (зеленых) и выходных (синих) параметров для функции Test():
double inpTest[] - входные параметры теста (двухмерные данные в одномерном массиве, старейшие идут вначале)
double outTest[] - Одномерный массив выходных параметров для сохранения выходных данных сети после обучения (старейшие идут вначале)
int ntt - # наборов в тестировании
double extInitWt[] - одномерный массив входов для сохранения трехмерного массива внешних начальных весов
int numLayers - # слоев, включая входной, скрытый и выходной
int lSz[] - # нейронов в слоях. lSz[0] # входов сети
int AFT - Тип функции активации нейронов (0:sigm, 1:tanh, 2:x/(1+x))
int OAF - 1 — разрешенная функция активации для выходного слоя; 0 — запрещенная
От того, используется ли функция активации в выходном слое (значение параметра OAF), зависит характер выходов. Если выходы бинарные, что часто встречается в случае решения проблем классификации, то функция активации должна использоваться в выходном слое (OAF=1). Пожалуйста, обратите внимание на то, что функция активации #0 (сигмоид) имеет уровни насыщения 0 и 1, а функции активации #1 and #2 — уровни насыщения -1 и 1. Если в выходах сети будут содержаться ценовые прогнозы, то в этом слое функция активации не нужна (OAF=0).
Примеры использования библиотеки нейронной сети:
BPNN Predictor.mq4 - прогнозы будущей цены открытия. Входы сети — относительные изменения цены:
x[i]=Open[test_bar]/Open[test_bar+delay[i]]-1.0
где замедление[i] рассчитывается как число Фибоначчи (1,2,3,5,8,13,21..). Выход сети - спрогнозированное следующее относительное изменение цены. Функция активации в выходном слое выключена.
Входные параметры индикатора:
extern int lastBar - последний бар в прошлых данных
extern int futBars - # будущих баров для прогноза
extern int numLayers - # слоев, включая входной, скрытый и выходной(2..6)
extern int numInputs - # входов
extern int numNeurons1 - # нейронов в первом скрытом или выходном слое
extern int numNeurons2 - # нейронов во втором скрытом или выходном слое
extern int numNeurons3 - # нейронов в третьем скрытом или выходном слое
extern int numNeurons4 - # нейронов в четвертом скрытом или выходном слое
extern int numNeurons5 - # нейронов в пятом скрытом или выходном слое
\ extern int ntr - # наборов обучения
extern int nep - максимальное # эпох
extern int maxMSEpwr - наборы maxMSE=10^maxMSEpwr; обучение останавливается < maxMSE
extern int AFT - тип функции активации (0:sigm, 1:tanh, 2:x/(1+x))
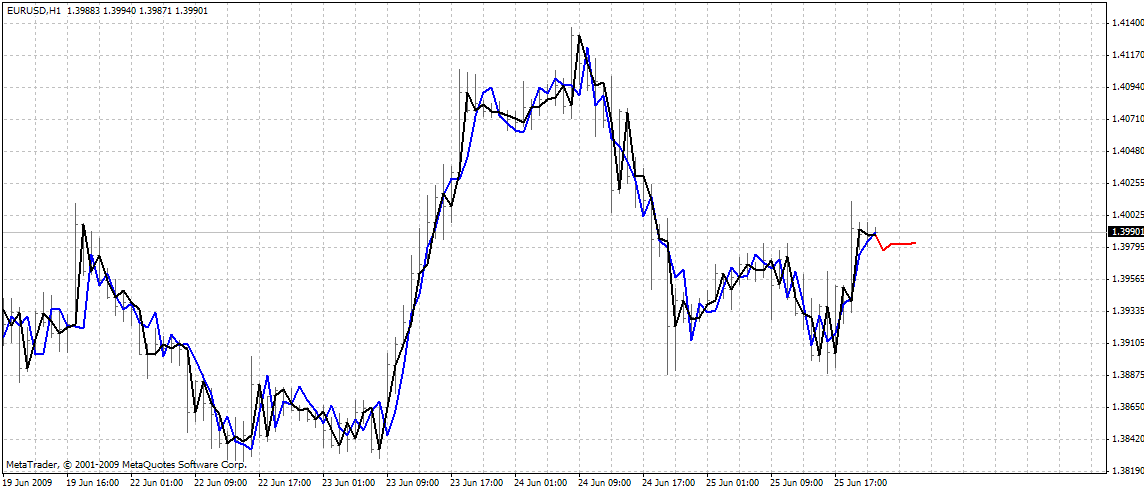
ИНдикатор строит три кривых на графике:
- красная - прогноз будущей цены
- black color - прошлые цены открытия, которые во время обучения были использованы как ожидаемые выходы сети
- blue color - выходы сети, полученные при обучении на заданных входных данных
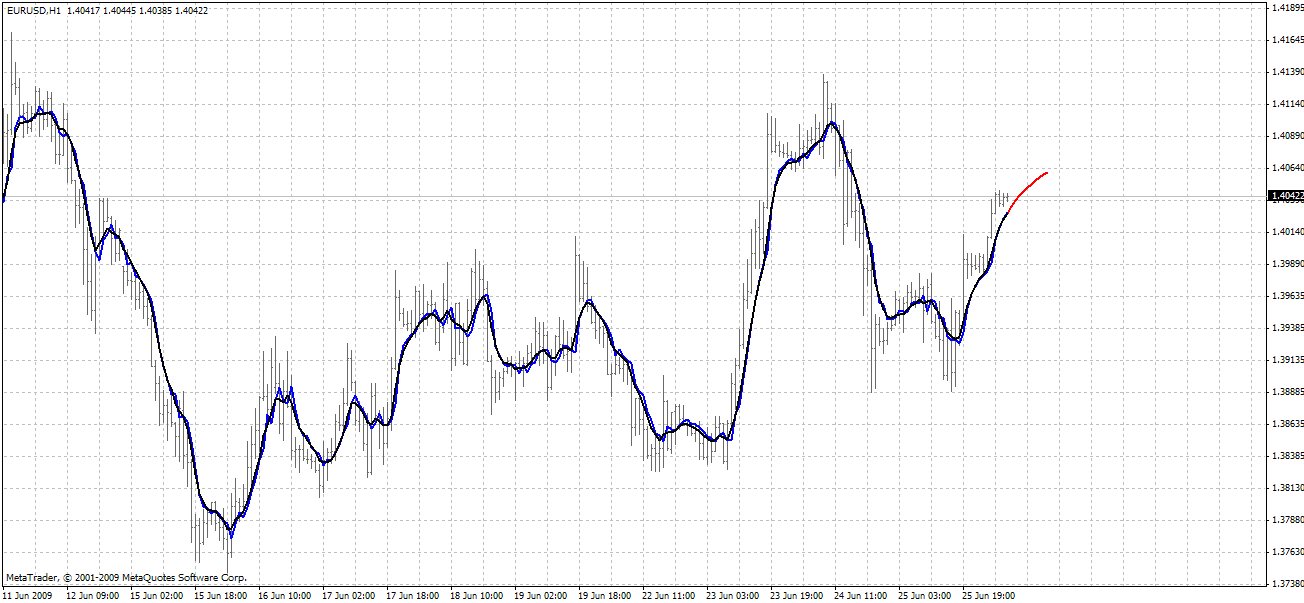
BPNN Predictor.mq4 - спрогнозированные сглаженные будущие цены открытия Используется EMA-сглаживание с периодом smoothPer.
Общие настройки:
- Скопируйте приложенный файл BPNN.DLL в C:\Program Files\MetaTrader 4\experts\libraries
- В терминале: Tools - Options - Expert Advisors - Allow DLL imports
Также вы можете скомпилировать ваш собственный файл DLL с использованием исходного кода в BPNN.zip.
Рекомендации:
- Сеть с тремя слоями (numLayers=3: один входной, один скрытый и один выходной) обычно достаточна в подавляющем большинстве случаев. В соответствии с теоремой Цыбенко, сеть с одним скрытым слоем способна аппроксимировать любую непрерывную многомерную функцию с любой желаемой степенью точности. Сеть с двумя скрытыми слоями способна аппроксимировать любую дискретную многомерную функцию.
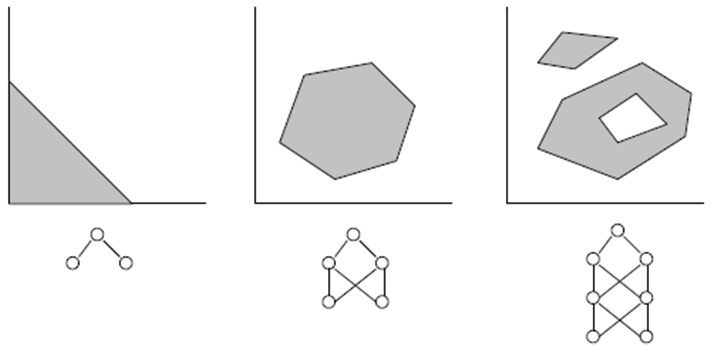
- Оптимальное количество нейронов в скрытом слое может быть найдено методом проб и ошибок. Следующие "правила большого пальца" можно найти в литературе: # скрытых нейронов = (# входов + # выходов)/2, или SQRT(# входов * # выходов). Отчет об ошибках обучения демонстрируется в специальном окне эксперта.
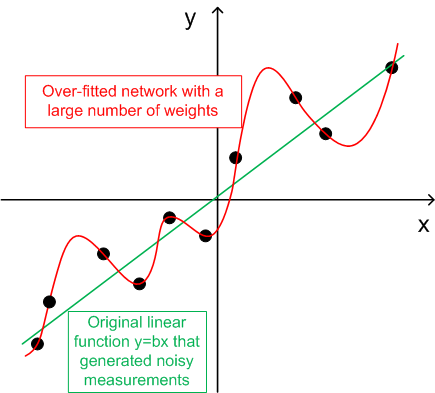
- Для генерализации количество обучающих наборов должно быть в 2 - раз больше общей цифры весов в сети. К примеру, по умолчанию BPNN Predictor.mq4 использует сеть с параметрами 12-5-1. Общая сумма весов составляет (12+1)*5+6=71. Поэтому число обучающих наборов должно быть как минимум 142. Общее представление о генерализации и "меморизации" (переобучении) демонстрируется на графике ниже.
- Входные данные в сети должны быть преобразованы в стационарные. Цены на Forex - не стационарные, а динамические. Также рекомендуется нормализовать входные параметры в диапазон -1 ... +1.
На графике ниже показана линейная функция y=b*x (x-вход, y-выход), выходы которой искажены шумом. Этот добавленный шум приводит к тому, что функция измерения выходов (черные точки) отклоняется от прямой линии. Функция y=f(x) может быть модифицирована добавлением данных из нейронной сети. Сеть с большим количеством весов может исключить ошибки в измерении данных. Ее поведение показано на графике как красная кривая, проходящая через все черные точки. Тем не менее, эта красная линия не имеет ничего общего с оригинальной линейной функцией (зеленая линия). Когда эта нейронная сеть используется для прогнозирования будущих значений y(x), это приводит к крупным ошибкам из-за "рандомности" добавленного шума.
В ответ на публикацию этих кодов, автор обращает к вам небольшую просьбу. Если вы способны создать прибыльную торговую систему на основе этого кода, пожалуйста поделитесь со мной своей идеей на электронный адрес vlad1004@yahoo.com.
Удачи!
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная публикация: https://www.mql5.com/en/code/9002
 NirvamanImax
NirvamanImax
EA со стоп-лоссом
 Fractal Dimension Index. + Step EMA
Fractal Dimension Index. + Step EMA
Индекс линейно взвешенной фрактальной размерности (фильтр тренд/отсутствие тренда), плюс Step EMA.